The Rust Programming Language:Understanding Ownership
所有权(Ownership)是Rust最独特的特性,它使Rust能够在不需要垃圾收集器的情况下保证内存安全,因此理解所有权是很重要的。在本章中,我们将会讨论所有权以及相关的几个特性:借用(borrowing),切片(slices),以及Rust如何在内存中分布数据。
What Is Ownership?
所有权是一组规则,规范Rust程序如何管理内存。所有程序在运行时都需要管理它们使用计算机内存的方式。一些语言具有垃圾收集器,能够在程序运行时定期寻找不再使用的内存;在其他一些语言中,程序员需要显式地分配和释放内存。Rust采用了第三种方式:内存通过一套所有权规则进行管理,编译器会检查这些规则。如果违反了任何规则,程序都将无法编译。所有权的任何特性都不会减慢程序运行的速度。
在本章节中,我们将会通过一些示例来学习所有权,这些示例专注于一种非常常见的数据结构:字符串。
The Stack and the Heap
一般的编程语言不会要求你经常考虑堆栈问题,但在像Rust这种“System programming language”当中,一个值是分配在堆还是栈中会影响语言的行为。因此,在介绍所有权之前,先对堆栈这一前置知识做一个简要的说明。
堆和栈都是内存的不同部分,它们在代码运行时可用,但会被以不同的结构组织。栈会按照接收值的顺序存储它们,并以相反的顺序移除值。这被称为后进先出(last in, first out)。在栈中添加数据被称为推入栈(pushing into the stack),而移除数据被称为弹出栈(popping off the stack)。栈上存储的所有数据都必须有已知的固定大小。编译时大小未知或者是大小可能发生变化的数据必须被存储在堆上。
堆的组织性相对来说较弱。当你把数据放到堆中时,你会请求一定大小的空间。内存分配器会在堆中寻找一个足够大小的空位,把它标记为使用中的状态,并返回一个指针,指向该位置的地址。整个过程被称为在堆上分配(allocating on the heap),有时也被简单地称为分配(allocating)。将值推入栈中不被视作分配。由于指向堆堆指针大小是已知、且固定的,所以你可以将这个指针存在栈上。 但是如果你想要实际的数据时,你必须跟随指针。
推入栈这个动作是要比在堆上分配更快的,因为不需要寻找一个用来存放新数据的位置,这个位置总是在栈的最顶端。
访问堆中的数据是要比访问栈中的数据更慢的,因为你必须通过指针进行访问。当代处理器如果在内存当中做的跳转更少,就会变得更快。
当在代码中调用一个函数时,传递给函数的值(可能包括指向堆的指针)和函数的局部变量都会被推入栈中。 当函数结束时,这些值都会从栈中弹出。
跟踪代码的哪些部分正在使用堆上的数据,最小化堆上重复数据的数量,以及清理未使用的堆数据以免用完空间,这些都是所有权要解决的问题。一旦你理解了使所有权,你就不需要经常考虑堆和栈,但是知道所有权的主要目的是管理堆数据可以帮助解释为什么它要以这种方式来工作。
Ownership Rules
首先,让我们来看看所有权规则:
- Rust中的每个值都有一个所有者。
- 一次只能有一个所有者。
- 当所有者超出作用域时,值将会被抛弃。
Variable Scope
作为所有权的第一个示例,我们将会观察变量的作用域。作用域是程序中某个项的有效范围。对于以下变量:
1 | let s = "hello"; |
变量s指向一个字符串字面量,这个字符串是在程序当中硬编码的。这个变量在它被声明的地方直到当前作用域的结尾都是有效的:
1 | { // s is not valid here, it's not yet declared |
The String Type
我们想要观察在堆中存储的数据,并探索Rust是如何知道何时清理它的。String类型是一个很好的示例。
我们将关注String当中与所有权相关的部分。这些方面也适用于其他复杂的数据类型,无论是由标准库提供还是由你创建。我们将在后续的章节中更深入地讨论String类型。String类型管理堆上分配的数据,因此能够存储在编译时对我们来说大小未知的文本。你可以使用from函数来从字符串字面量创建一个String:
1 | let s = String::from("hello"); |
这种字符串与字符串字面量不同的是,它是可变的:
1 | let mut s = String::from("hello"); |
所以,为什么String可以被修改,但是字面量不能?它们的差异在处理内存的方式上。
Memory and Allocation
对于字符串字面量而言,我们在编译期就能知道它的内容,所以这个值是直接硬编码到最终的可执行文件中的。这就是为什么字符串字面量是快速且高效的。但是这些优点只来源于字符串字面量的不可变性。不幸的是,我们不能为了每个在编译期大小未知,且在运行时大小可能改变的文本,而将一块内存放入二进制文件中。
对于String类型,为了支持一个可变的,可增长的文本片段,我们需要在堆上分配一块在编译期未知大小的内存来存储内容。这意味着:
- 这块内存必须在运行时被内存分配器请求。
- 当我们完成了对
String的使用时,我们需要有一种方式将这块内存返回给分配器。
第一部分是由我们来完成的:当我们调用String::from时,它的实现请求了所需的内存。
然而,第二部分是不同的。在有GC的语言当中,GC会跟踪并清除不再被使用的内存,我们就不需要再考虑它了。在大多数没有GC的语言当中,就需要由我们来识别内存何时不再使用,并调用代码来显式释放它,就和我们请求它时所做的一样。正确地做到这一点一直是一件困难的事情。如果我们忘记了,我们就会浪费内存。如果我们做得太早,我们就会有一个无效的变量。如果我们做了两次,也会出现bug。我们需要精确地将一个allocate与一个free进行配对。
Rust选择了一个不同的道路:一旦拥有内存的变量超出作用域,那么这块内存会被自动释放。当一个变量超出作用域时,Rust会为我们调用一个特殊的函数drop,这也是String的作者可以放置释放内存代码的地方。Rust会在闭合的大括号处自动调用drop。
这个模式对Rust代码的编写方式产生了深远的影响。现在看起来可能很简单,但在更复杂的情况下——我们希望多个变量使用我们在堆上分配的内存时,代码的行为可能是意想不到的。让我们现在探索部分这些情况。
Variables and Data Interacting with Move
在Rust中,多个变量可以以不同的方式与相同的数据交互。让我们看一个整数的示例:
1 | let x = 5; |
现在我们有了两个变量,x和y,它们的值都是5。因为整数是已知的,具有固定大小的简单值,因此这两个5都会被压入栈中。
现在让我们来看看String的情况:
1 | let s1 = String::from("hello"); |
这看起来很相似,所以我们猜测它的工作方式可能是相同的:也就是说,第二行将s1的值复制一份并绑定到s2上。但其实不然。
下图可以让我们了解字符串内部存在什么。一个字符串由三个部分组成,如左侧所示:指向存储字符串内容的内存的指针、长度和容量。这组数据存储在栈上。右侧是存储内容的堆上的内存。
长度是当前字符串内容使用的内存量,单位为字节。容量是字符串从分配器接收到的总内存量,单位也为字节。长度和容量之间的差异很重要,但在当前的上下文中不是很重要,因此目前可以忽略容量。
当我们将s1赋值给s2时,String数据被复制,这意味着复制了在栈上的指针,长度和容量。我们不会复制指针指向的堆内存。就像下图这样:
刚刚我们提到:当变量超出作用域时,Rust会自动调用drop函数来释放这个变量的对内存。但上图显示了两个指针指向同一个位置。那么就有一个问题:当s2和s1超出作用域时,它们都会尝试释放相同的内存。这被称为双重释放错误(double free error),是我们之前提到的内存安全错误之一。两次释放内存可能导致内存损坏,这可能会导致安全漏洞。
为了保证内存安全,在let s2 = s1之后,Rust会将s1视为不再有效。因此,当s1超出作用域时,Rust不需要释放任何东西。看看在创建s2之后尝试使用s1会发生什么;这将不起作用:
1 | let s1 = String::from("hello"); |
运行产生报错如下:
1 | cargo run |
如果你了解浅拷贝(shallow copy)和深拷贝(deep copy),这里的复制看起来会像是浅拷贝。但由于Rust还会使第一个变量无效,因此它被称为移动(move),而不是浅拷贝。在这个例子中,我们会说s1被移动到了s2当中。
此外,这暗示了一个设计选择:Rust永远不会自动创建数据的“深度”副本。因此,任何自动复制都可以认为在运行时性能方面是低成本的。
Scope and Assignment
这与作用域、所有权和通过drop函数释放内存之间的关系正好相反。当你为现有变量分配一个全新的值时,Rust会调用drop并立即释放原始值的内存。例如:
1 | let mut s = String::from("hello"); |
我们首先声明了一个变量s,并将其绑定到一个值为"hello"的字符串上。然后,我们立即创建一个新的字符串,值为"ahoy",并将其赋值给s。现在将不会有任何东西指向堆中的原始值。
因此,原始字符串超出了作用域,Rust会马上调用drop函数释放这块内存。
Variables and Data Interacting with Clone
当我们想深拷贝String的堆内存,而不仅仅是栈中的数据时,我们可以使用clone方法。例如:
1 | let s1 = String::from("hello"); |
Stack-Only Data: Copy
还有一个问题我们没有谈到。那就是为什么以下的代码是有效的:
1 | let x = 5; |
但这与我们刚刚学到的好像冲突了,我们没有调用clone,但x仍然有效,且并没有移动到y。
原因是,像整数这种在编译期已知大小的类型是完全存在栈中的,所以对实际值的复制是很快速的。这意味着我们没有理由在创建变量y后阻止x有效。换句话说,这里的深拷贝和浅拷贝没有区别,所以调用clone不会做任何与浅拷贝不同的事。
Rust有一种特殊的注解,叫做复制特质(Copy trait),我们可以把它放在像整数一样存储在栈中的类型上。如果一个类型实现了Copy trait,那么它的变量就不会移动,而是被简单复制,从而在赋值给另一个变量后仍然有效。
如果一个类型或其任何部分已经实现了Drop trait,Rust不会让我们为该类型添加Copy注解。如果该类型需要在值类型超出作用域时做一些特殊处理,而我们又为其添加了Copy注解,那么就会出现编译期错误。
Ownership and Functions
将一个值传递给一个函数的机制与给变量赋值是很相似的,也会产生移动或者是复制。例如:
1 | fn main() { |
Return Values and Scope
返回值也会转换所有权。例如:
1 | fn main() { |
变量的所有权每次都遵循相同的模式:为另一个变量赋值会移动它。当包含堆中数据的变量退出作用域时,除非数据的所有权已经转移到另一个变量,否则该值将被drop清理。
虽然这种方法可行,但是在每个函数中获取所有权并返回所有权有点繁琐。如果我们想让一个函数使用一个值,但是不想让其剥夺所有权,我们该怎么做呢?我们传入的任何数据如果想再次使用,都需要传回。此外,我们可能还想返回函数主体产生的任何数据,这让人非常恼火。
Rust让我们能够通过元组返回多个值:
1 | fn main() { |
但是,对于一个本应该很常见的概念来说,这太麻烦了。幸运的是,Rust有一种传递值却不转移所有权的功能,叫做引用(references)。
References and Borrowing
在上面这个calculate_length的例子当中,我们可以用另一种方式,也就是提供一个指向这个String的引用。一个引用就像一个指针,它是一个我们可以跟踪访问存储在该地址的数据的地址;该地址由其他变量拥有。与指针不同的是,引用保证在引用的生命周期内指向特定类型的有效值。
这里有一个例子,这个函数将对象的引用作为参数,而不是直接获取这个值的所有权:
1 | fn main() { |
可以看到,我们把&s1传入了calculate_length,并且在其参数定义中,我们使用了&String而不是String。这些符号表示引用,它们允许你引用某个值而不抢占其所有权。下图表示了它们之间的关系:
让我们来详细看看这里的函数调用:
1 | let s1 = String::from("hello"); |
由于这个创建的引用&s1并没有抢占其所有权,因此它指向的值在它停止使用时也不会被销毁:
1 | fn calculate_length(s: &String) -> usize { // s is a reference to a String |
也就是说,这里的s指向的值在s停止使用时并不会被释放,因为s并不拥有该值。
我们称创建引用的行为为借用(borrowing)。
那么,当我们尝试修改借用的值时,会发生什么呢?
1 | fn main() { |
这里会产生报错:
1 | cargo run |
引用也和变量一样,默认是不可变的。
Mutable References
我们只需要做一点点的小改动就可以获得一个可变的引用:
1 | fn main() { |
首先我们将变量s修改为mut,然后在change函数的参数中也加上mut,并且在调用时也加上mut。这清楚地表明了,change会改变借用的值。
可变的引用有一个很大的限制条件:一个值有且只可有一个可变引用。以下代码试图对s创建两个可变引用:
1 | let mut s = String::from("hello"); |
这会产生报错:
1 | cargo run |
阻止在同一时间对同一数据进行多个可变引用的限制允许了进行变更,但方式非常受控。设定这个限制的好处是Rust可以在编译时防止数据竞争(data race),也就是并发写的问题。
我们可以创建一个新的作用域来允许多个可变变量:
1 | let mut s = String::from("hello"); |
Rust对可变引用和不可变引用混合使用的情况也制定了类似的规则:
1 | let mut s = String::from("hello"); |
这也会产生报错:
1 | cargo run |
我们同样不能在拥有一个不可变引用的情况下,对同一个变量创建一个可变引用。但是再继续创建不可变引用是可以的。
注意,引用的作用域从它被引入的地方开始,并持续到最后一次使用该引用为止。例如以下代码是可以编译成功的:
1 | let mut s = String::from("hello"); |
Dangling References
在包含指针的编程语言当中,很容易会创建出一个悬空指针——一个引用了可能已经被其他人使用的内存位置的指针——通过释放某些内存而保留对该内存的指针。而在Rust中,编译器保证引用永远不会是悬空引用:如果你有对某些数据的引用,编译器将确保数据不会在指向它的引用超出作用域之前超出作用域。
如果尝试创建一个悬空引用,那就会产生编译时报错:
1 | fn main() { |
报错如下:
1 | cargo run |
错误信息中提到了我们尚未接触到的概念:lifetimes。我们将在后面讨论它。但其中包含了关键的错误信息:
1 | this function's return type contains a borrowed value, but there is no value for it to be borrowed from |
让我们看看dangle中到底发生了什么:
1 | fn dangle() -> &String { // dangle returns a reference to a String |
当dangle函数结束时,s所占用的内存将会被释放。但我们尝试返回对它的引用。这意味着这个引用将会指向一个无效的String。
The Slice Type
Slices(切片)让你能引用集合中的一个元素序列,而不是整个集合。切片是一种引用,所以它没有所有权。
有一个小的编程问题:编写一个函数,从一个被空格分割的字符串序列中获取第一个字符串。如果这个序列中没有空格,则返回整个序列作为一个字符串。
让我们看看如果不用切片的话,我们的方法应该如何定义:
1 | fn first_word(s: &String) -> ? |
这个函数有一个&String类型的参数。我们不需要获取它的所有权(在Rust通常的写法中,函数都不会抢夺参数的所有权,除非必要情况)我们该返回什么呢?我们还没有一种方式可以表示“字符串的一部分”。然而,我们可以返回首个字符串末尾字符的下标,这是由空格来决定的。就像这样:
1 | fn first_word(s: &String) -> usize { |
现在我们能够找到第一个字符串的截止下标了,但有一个问题。我们单独返回了一个usize,但是它只在&String这个上下文中才是有意义的。也就是说,因为它是与String分离的一个值,因此不能保证它能否在未来一直有效。可以考虑如下情况:
1 | fn main() { |
这里的数据同步问题是很容易出错的。如果我们写一个类似的second_word函数,管理这些索引会变得更容易出问题:
1 | fn second_word(s: &String) -> (usize, usize) {} |
幸运的是,Rust提供了字符串切片来解决这个问题。
String Slices
字符串切片是对String的一部分的引用,它看起来像这样:
1 | let s = String::from("hello world"); |
这里的下标也是左闭右开的区间。这里的world是一个指针指向s中下标为6的位置,并且长度为5。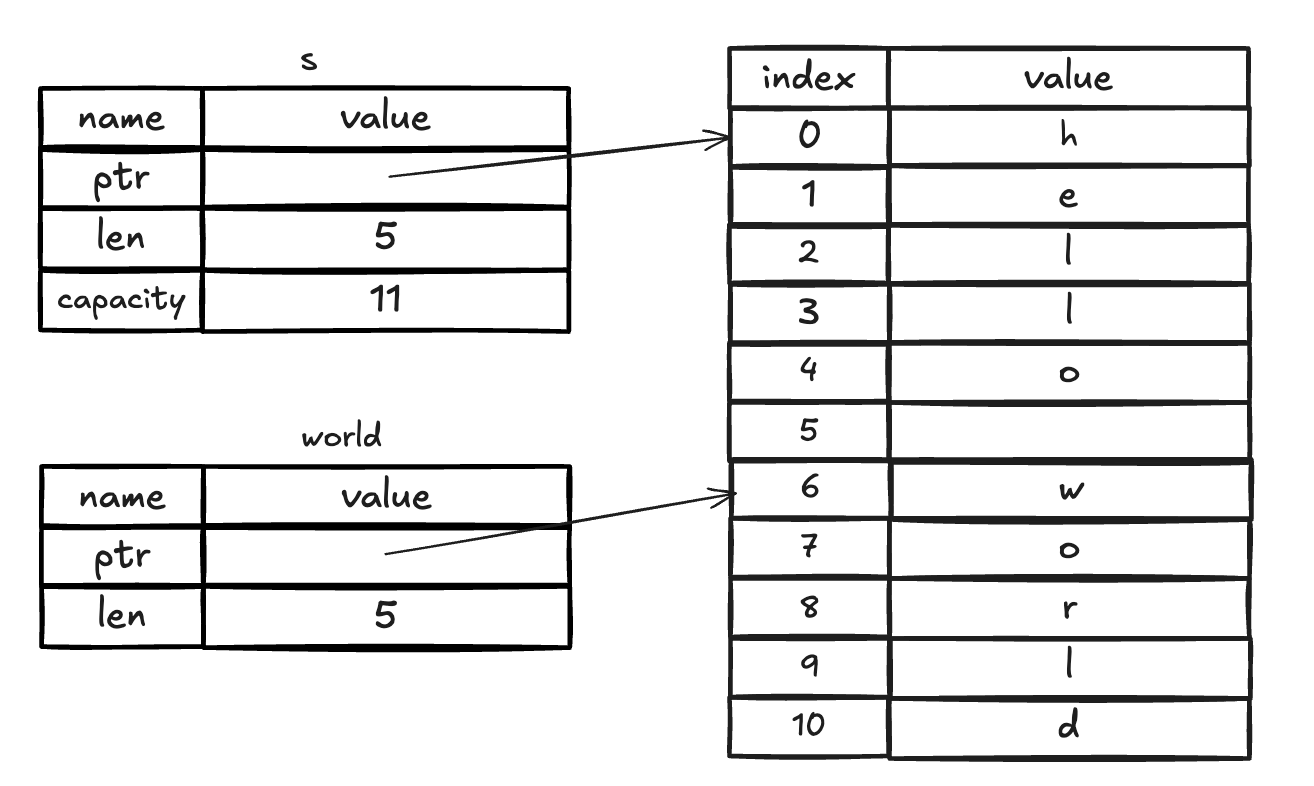
如果你想要创建一个从下标0开始的切片,则可以把0省略:
1 | let s = String::from("hello"); |
同样,如果切片包含最末尾的字符,也可以省略:
1 | let s = String::from("hello"); |
也可以头尾都省略,直接获取对整个字符串的切片:
1 | let s = String::from("hello"); |
注意:字符串切片范围索引必须位于有效的UTF-8字符边界上。如果尝试在多字节字符的中间创建字符串切片,则会报错退出。
现在,我们可以用字符串切片来重写first_word函数:
1 | fn first_word(s: &String) -> &str { |
现在,first_word函数的返回值与s就是绑定的。
我们再来测试一下之前那个会产生bug的情况,现在它会直接抛出一个编译时错误:
1 | fn main() { |
报错信息如下:
1 | $ cargo run |
回忆借用规则,如果我们有一个不可变引用,那么我们就不能同时再获得一个可变引用。因为clear会清除s,因此它需要获取一个可变引用。而在调用println!时使用了word中的引用&s,因此不可变引用仍然存活。这时s同时存在一个可变引用和一个不可变引用,因此编译失败。
String Literals as Slices
回想一下我们谈过字符串字面量是存储在binary当中的。现在我们知道了切片,就可以正确理解字符串字面量:
1 | let s = "Hello world!"; |
这里s的类型是&str,它是指向binary特殊位置的一个切片。这也是为什么字符串字面量是不可变的,因为&str是一个不可变的引用。
String Literals as Parameters
经验更丰富的Rustaceaan会写出这样的方法签名,因为我们可以在&String和&str上使用相同的函数:
1 | fn first_word(s: &str) -> &str { |
使用切片而不是字符串更加灵活,它利用了deref coercions(解引用强制转换)这一特性,我们会在后面的章节讲解它。
定义一个获取字符串切片而不是一个对String的引用的函数会让我们的API更通用:
1 | fn main() { |
Other Slices
字符串切片是专门针对字符串的切片,当然还有更通用的切片类型,例如数组的切片:
1 | let a = [1, 2, 3, 4, 5]; |
这个切片的类型为&[i32]。它是一个存储了指向第一个元素的指针和长度的引用,类似字符串切片。你也可以在其他类型的集合中使用这种切片。
Summary
所有权、借用和切片的概念确保了 Rust 程序在编译时的内存安全。Rust 语言以与其他系统编程语言相同的方式让你控制内存使用,但由于数据的所有者在超出作用域时会自动清理该数据,因此你不必编写和调试额外的代码来获得这种控制。
所有权影响 Rust 的许多其他部分,因此我们将在本书的其余部分进一步讨论这些概念。