Golang基础学习笔记,部分来自刘丹冰老师课程中学习到的内容
目录结构
golang/src/project01/main
- golang:设置的
GOPATH路径 - src:存放项目源代码
- project01:项目根路径
- main:模块(包)名
Hello World
1 | package main // 声明文件所在在包,每个文件必须有归属的包 |
手动编译后运行(会生成.exe文件):
1 | go build test.go |
直接编译运行(不生成.exe文件):
1 | go run test.go |
以上两种方式的区别:
- 在编译(
go build)时,编译器会将程序运行依赖的库文件包含在可执行文件中,所以,可执行文件变大了很多 - 如果我们先编译生成了可执行文件,那么我们可以将该可执行文件拷贝到没有go开发环境的机器上,仍然可以运行
- 如果我们是直接
go run,那么就需要go的开发环境才能执行
包
import的实际上是包的路径,基于$GOPATH/src/为根目录,使用的时候采用包名.函数名的方式进行调用- 在一个目录下的文件必须归属于同一个包
- 可以给包取别名,取别名后,原来的包名就不能使用了
1
2
3
4import format "fmt"
fmt.Println() // Error
变量
1 | var age int |
- 如果没有赋值, 就会使用默认值(零值)
- 如果没有写变量的类型, 那么会根据等号后的值进行自动类型推断(例如
var age = 18)
1 | // 定义多个变量 |
1 | // 定义全局变量 |
数据类型
- 整数类型:int、int8、int16、int32、int64、uint、uint8、uint16、uint32、uint64、byte。默认为int类型,数字代表比特位数
- int/uint的大小和操作系统位数有关,在32位的系统下为4字节,在64位的系统下为8字节
- rune等价于int32,byte等价于uint8
- 浮点类型:float32、float64。默认为float64类型
- 字符类型:Golang中没有专门的字符类型,如果要存储单个字符的话,一般用byte来保存
- 布尔类型:bool
- 字符串类型:string。字符串是不可变的。可以用反引号定义多行字符串。
1
2
3
4
5var s string = "abc" + "abc" + "abc" + "abc" + "abc" + "abc" + "abc" + "abc"
// 如果要分为多行的话,要保证操作符在末尾,因为go会自动在每行的末尾加上分号,如果放在每行开头则会报错
var s string = "abc" + "abc" + "abc" +
"abc" + "abc" + "abc" + "abc" + "abc" - 指针:
*数据类型,例如*int、*float32
类型转换
Go在不同类型的变量之间赋值时需要显式转换,并且只有强制类型转换,不存在隐式转换
1 | var num int64 = 12 |
将基本数据类型转为string类型:
fmt.Sprintf()strconv.FormatXxx()
将string类型转为基本数据类型:
strconv.ParseXxx()
标识符
下划线_本身在Go中是一个特殊的标识符,称为空标识符。可以代表任何其它的标识符,但是它对应的值会被忽略,所以仅能被作为占位符使用。
1 | import ( |
起名规则:
- 尽量保持
package的名字和目录保持一致main包是程序的入口包,所以要将main函数所在的包定义为main包,如果不这样做,就无法通过
go run运行,也无法通过go build得到可执行文件注意:包名是从
$GOPATH/src/后开始计算的 - 变量名、函数名、常量名都采用驼峰命名
- 如果变量名、函数名、常量名首字母大写,则可以被其它的包访问;否则只能在本包中使用
运算符
在go语言中,++,--操作非常简单,只能单独使用,不能参与到运算当中去。并且只能在变量的后面,不能写在变量的前面
获取用户终端输入
1 | // Scanln |
对于/,在go语言中是整数除法,如果要做小数除法的话需要进行类型转换
流程控制
分支
在go语言中,**if后的{}一定不能省略**,并且在if后面可以并列地加入变量的定义
1 | if count := 20; count < 30 { |
注意if-else的格式规范:
1 | // 正确示范 |
switch注意事项:
switch后是一个表达式case后面的表达式如果是常量值,则要求不能重复case后各个值的数据类型,必须和switch的表达式数据类型一致case后可以带多个值,使用逗号间隔,例如case value1, value2, value3..case后不需要breakdefault语句不是必须的,位置也是随意的switch后也可以不带表达式,当作if分支来使用switch后也可以直接声明/定义一个变量,以分号结束1
2
3switch variable := 18; {
// ...
}- 可以使用
fallthrough进行switch穿透,直接执行下一个case(不再检查这个case是否满足,直接执行)1
2
3
4
5
6
7switch count {
case 1:
fmt.Println("something...")
fallthrough
case 2:
fmt.Println("something others...")
}
循环
循环结构只有for,没有while
1 | for i := 0; i < 10; i++ { |
需要注意的是,**for循环是按照字节进行遍历输出的**,而对于中文的情况,每个字符占用三个字节,需要进行额外考虑
使用break + label跳出指定循环:
1 | outer: |
同理,还有continue + label的用法
函数
1 | func 函数名(形参列表) (返回值类型列表) { |
- 基本数据类型和数组默认都是值传递的
- go语言中的函数不支持重载
- 支持可变参数,并且在处理可变参数的时候,将可变参数当作切片来处理
1
2
3
4
5func test(args...int) {
for index, value := range args {
// ...
}
} - 以值传递方式传递的变量类型,如果希望在函数内的变量能修改函数外的变量,可以传入变量的地址,在函数内以指针的形式操作变量
- 在go中,函数也是一种数据类型,可以赋值给一个变量,则该变量就是一个函数类型的变量了。通过该变量可以进行函数调用
- go语言支持自定义数据类型,例如:
type myInt int,可以理解为起了一个别名,但是在使用的时候,例如将一个int类型的值赋值给一个myInt类型的值,编译器还是会认为这是两种不同的数据类型,需要进行强制类型转换 - 可以支持对返回值进行命名
1
2
3
4
5func cal(num1 int, num2 int) (sum int, sub int) {
sub := num1 - num2
sum := num1 + num2
return
}
init函数
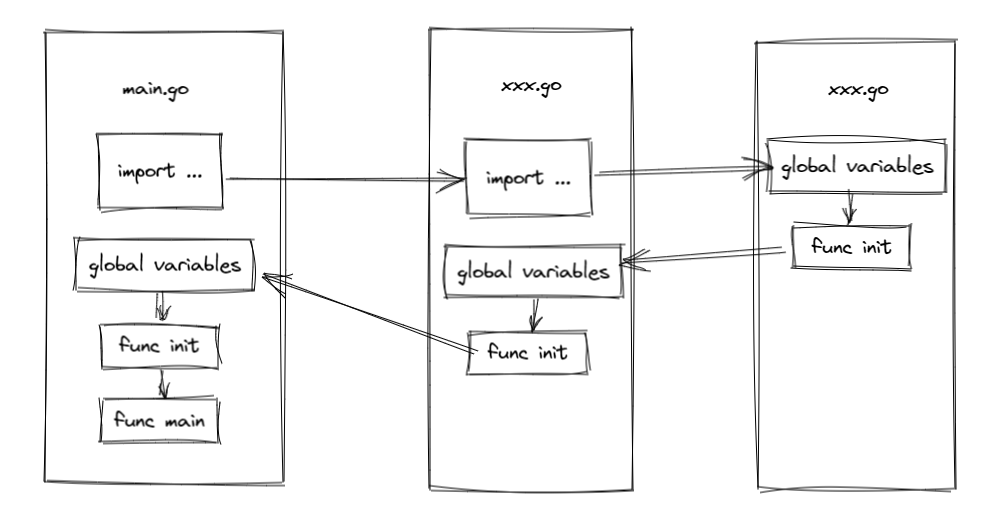
init函数:初始化函数,可以用来进行一些初始化的操作。每个源文件都可以包含一个init函数,该函数会在main函数执行前被调用- 全局变量定义,
init函数,main函数的执行流程:全局变量定义 ->init函数 ->main函数。如果存在互相引用的多个源文件,则执行顺序为:
匿名函数
1 | sub := func (num1 int, num2 int) int { |
闭包
闭包就是一个函数和与其相关的引用环境组成的一个整体
1 | package main |
需要注意,闭包中使用的变量/参数会一直保存在内存中,所以不可滥用
defer
当遇到defer关键字,会将后面的代码压入栈中,也会将相关的值同时拷贝入栈中,不会随着函数后面的变化而变化
1 | func add(num1 int, num2 int) int { |
应用场景:将释放资源的语句用defer修饰,就可以做到延迟释放
defer + recover错误处理机制
1 | package main |
recover只在defer调用的函数中有效,并且defer要在panic之前先注册,否则不能捕获异常。当panic被捕获到之后,被注册的函数将获得程序控制权。
panic与error的区别(有点类似Java中的Error和Exception):
- error可作为返回值返回,一般是可预知的,可以进行合适的处理,不会造成程序的终止
- panic一般是无法预知的异常,如空指针或者数组越界,会导致程序崩溃
数组
1 | var arr1 [3]int = [3]int{3, 6, 9} |
- 长度属于类型的一部分
- Go中数组属于值类型,在默认情况下是值传递,因此会进行值拷贝
- 如果想在其他函数中去修改原来的数组,可以使用引用传递
1
2
3
4
5
6
7
8
9
10
11
12
13package main
import "fmt"
func main() {
arr := [3]int{3, 6, 9}
test(&arr)
fmt.Println(arr)
}
func test(arr *[]int) {
(*arr)[0] = 8
}
切片
- 定义一个切片,然后让切片去引用一个已经创建好的数组
1
2var arr [6]int = [6]int{3, 6, 9, 1, 4, 7}
slice := arr[1:3] - 通过
make内置函数来创建切片1
2
3
4
5
6
7
8
9
10
11
12slice := make([]int, 4, 20)
fmt.Println(slice) // [0 0 0 0]
fmt.Println(len(slice)) // 4
fmt.Println(cap(slice)) // 20
slice[0] = 66
slice[1] = 88
fmt.Println(slice) // [66 88 0 0]
slice2 := []int{1, 4, 7}
fmt.Println(slice2)
fmt.Println(len(slice2)) // 3
fmt.Println(cap(slice2)) // 3
注意事项:
- 切片使用不能越界
- 简写方式:
var slice = arr[0:len(arr)] => var slice = arr[:] - 可以对切片继续切片
append函数:
1 | package main |
append函数不改变原切片- 当切片大小超出容量时,会创建一个新的底层数组,并将旧数组拷贝到新的数组中
映射
1 | package main |
- slice、map、function不可作为key
结构体
1 | package main |
如果两个变量分别所属的结构体类型不同,但是字段完全相同,就可以通过强制类型转换来进行赋值
1 | package main |
方法
1 | type A struct { |
- 这里相当于定义了结构体A的一个方法test,用
(a A)来体现方法test和结构体A的绑定关系(不一定是a,名字任意) - 结构体对象传入方法中时是值传递
- 如果想要在方法中改变结构体对象的字段,需要在方法中接收指针,例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18package main
import "fmt"
type Person struct {
Name string
Age int
}
func (p *Person) ChangeName() {
p.Name = "New Name"
}
func main() {
p := Person{"Bob", 30}
p.ChangeName()
fmt.Println(p)
} - 不一定是结构体,给基本数据类型如
int等起别名后,也可以给基本数据类型定义方法 - 如果一个结构体实现了
String()方法,那么在print的时候就会根据这个方法的返回值进行打印,类似Java中的toString()方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20package main
import "fmt"
type Person struct {
Name string
Age int
}
func (p *Person) String() string {
return fmt.Sprintf("%s is %d years old", p.Name, p.Age)
}
func main() {
p := Person{
Name : "Bob",
Age : 30
}
fmt.Println(&p)
}
封装
在go中的封装总的来说就是根据首字母大小写实现的权限控制机制
继承
1 | type Animal struct { |
- 结构体可以使用嵌套匿名结构体的所有字段和方法,即:首字母大写/小写的字段和方法都可以使用。例如如果上述结构体
Animal中的Age字段为age,也依然可以通过Cat.Animal.age来访问 - 匿名结构体字段访问可以简化。例如
Cat.Animal.Age可以简化为Cat.Age,会先查找Cat中是否存在Age字段,如果有就直接使用,否则进入嵌套的结构体内寻找 - 支持多继承,也就是一个结构体中可以嵌套多个结构体
- 结构体的匿名字段可以是基本数据类型
1
2
3
4
5type C struct {
int
}
c.int // 访问int字段 - 也可以嵌入匿名结构体的指针
1
2
3type C struct {
*A
} - 结构体的字段可以是结构体类型的(组合模式)
1
2
3
4
5
6type B struct {
}
type D struct {
c B
}
接口
Go语言中的接口是隐式实现的,也就是说,如果一个类型实现了一个接口定义的所有方法,那么它就是自动地实现了该接口
1 | package main |
- 接口本身不能创建实例,但是可以指向一个实现了该接口的自定义类型的变量
- 只要是自定义数据类型,就可以实现接口,不仅仅是结构体类型
- 一个自定义类型可以实现多个接口
- 一个接口可以继承多个别的接口。例如A接口继承了B接口和C接口,那么在实现A接口时就需要同时实现B接口和C接口中的方法
断言
用于判断是否是某个类型的变量的语法,类似Java中的instanceof:value, ok := element.(T),这里value就是变量的值,ok是一个bool类型,element是interface变量,T是断言的类型
- 也可以用
element.type()来获取接口变量的类型,然后搭配switch进行控制 interface{}万能指针可以指向任意类型的变量
反射
pair结构
在Golang中,变量包含两部分:type和value,type可能是static type(int、string…)或者是concrete type(interface指向的具体类型,系统能看得见的类型),value中保存的是具体的值。这里的type, value对就被称为pair结构
1 | package main |
在这里,无论怎么断言,b对应的pair结构都是不变的,而r之所以可以断言为Writer,就是因为他们的type都是Book,而Book实现了Reader和Writer这两个接口
reflect
使用reflect包下的TypeOf和ValueOf这两个方法可以获取到变量的类型和值
1 | package main |
tag
1 | package main |
tag的主要用途是建立结构体字段与json key的映射
1 | package main |
可以看出,tag中定义的json:key对应的就是json中的key
协程
GMP:G(goroutine,协程),M(内核线程),P(processor,协程调度器)
goroutine基本模型和调度策略
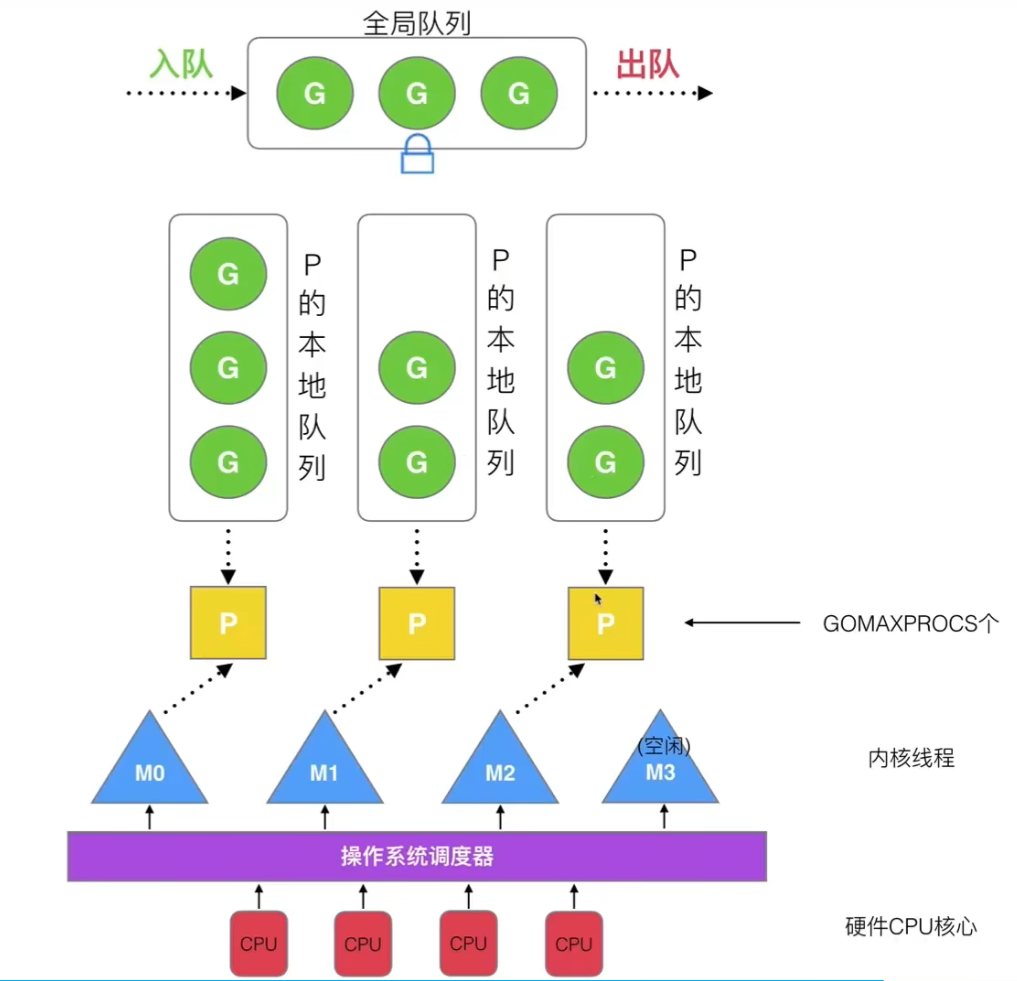
调度器的设计策略:复用线程(work stealing机制,hand off机制)、利用并行(GOMAXPROCS=CPU核心数/2)、抢占、全局G队列
创建一个goroutine
1 | package main |
子goroutine依赖于主goroutine,主goroutine结束后子goroutine也会结束执行
可以使用runtime.Goexit()退出当前的goroutine
channel
channel是用于协程间通信的一块数据区域,可以理解为一个管道
1 | package main |
对于这里的main goroutine和sub goroutine之间的数据通信,可以发现channel是阻塞读写的,写入后需要被读取才能继续向下执行,同理,读取操作也会阻塞等待有数据写入后再进行读取。以上channel被称为无缓冲的channel
而对于有缓冲的channel:
1 | package main |
当channel已满时,再向里面写数据,就会阻塞;当channel为空时,从里面取数据也会阻塞
channel的关闭特点
1 | package main |
channel不像文件一样需要经常去关闭,只有当你确实没有任何发送数据了,或者你想显式地结束range循环之类的,才去关闭channel- 关闭
channel后,无法向channel中再发送数据(引发panic错误后导致接收立即返回零值) - 关闭
channel后,可以继续从channel接收数据 - 对于
nil channel,无论收发都会被阻塞
range
对于:
1 | for { |
可以修改为:
1 | for data := range c { |
select
单流程下一个goroutine只能监控一个channel的状态,select可以完成监控多个channel的状态。select具备多路channel的监控状态功能
1 | select { |
Go Modules
GOPATH工作模式的弊端
- 无版本控制概念
- 无法同步一致第三方版本号
- 无法指定当前项目引用的第三方版本号
go mod命令:
- go mod init:生成go.mod文件
- go mod download:下载go.mod文件中指明的所有依赖
- go mod tidy:整理现有的依赖
- go mod graph:查看现有的依赖结构
- go mod edit:编辑go.mod文件
- go mod vendor:导出项目中所有的依赖到vendor目录
- go mod verify:校验一个模块是否被篡改过
- go mod why:查看为什么需要依赖某模块
go mod环境变量:
- GO111MODULE:表示是否开启go modules模式,建议go1.11后都设置为on
- GOPROXY:项目的第三方依赖库的下载源地址
- GOSUMDB:用来检验拉取的第三方库是否完整
- GONOPROXY
- GONOSUMDB
- GOPRIVATE:设置私有仓库,对这里的仓库将不会进行GOPROXY下载和校验
使用Go Modules初始化项目
首先要开启Go Modules模块:保证GO111MODULE环境变量的值为on,可以通过go env -w GO111MODULE=on或export GO111MODULE=on两种方式来修改
在初始化项目时,可以按照以下步骤:
- 任意文件夹创建项目(不要求在
$GOPATH/src) - 创建go.mod文件,指定当前项目的模块名称(
go mod init xxx)- 在该go.mod文件中会显示go版本、当前模块和依赖项等信息
- 在该项目下编写源代码
- 如果代码中依赖某个库,可以采用手动download(
go get xxx)或自动download(go run xxx)的形式下载依赖库 - 依赖库会存放到
$GOPATH/pkg路径下
- 如果代码中依赖某个库,可以采用手动download(
- 下载依赖库后,go.mod文件中会出现依赖库的信息
- 包含依赖库名称,依赖库版本,是否直接引用(
indirect表示间接引用,引用的是依赖库的某个子模块时会显示)
- 包含依赖库名称,依赖库版本,是否直接引用(
- 会生成一个go.sum文件,用于罗列当前项目的依赖库和版本,并做哈希校验,保证依赖库的版本不会被改动
修改模块依赖关系
可以使用go mod edit -replace=${old version}=${new version}来替换依赖库的版本号,对于go.mod文件的改动则会多一行replace语句